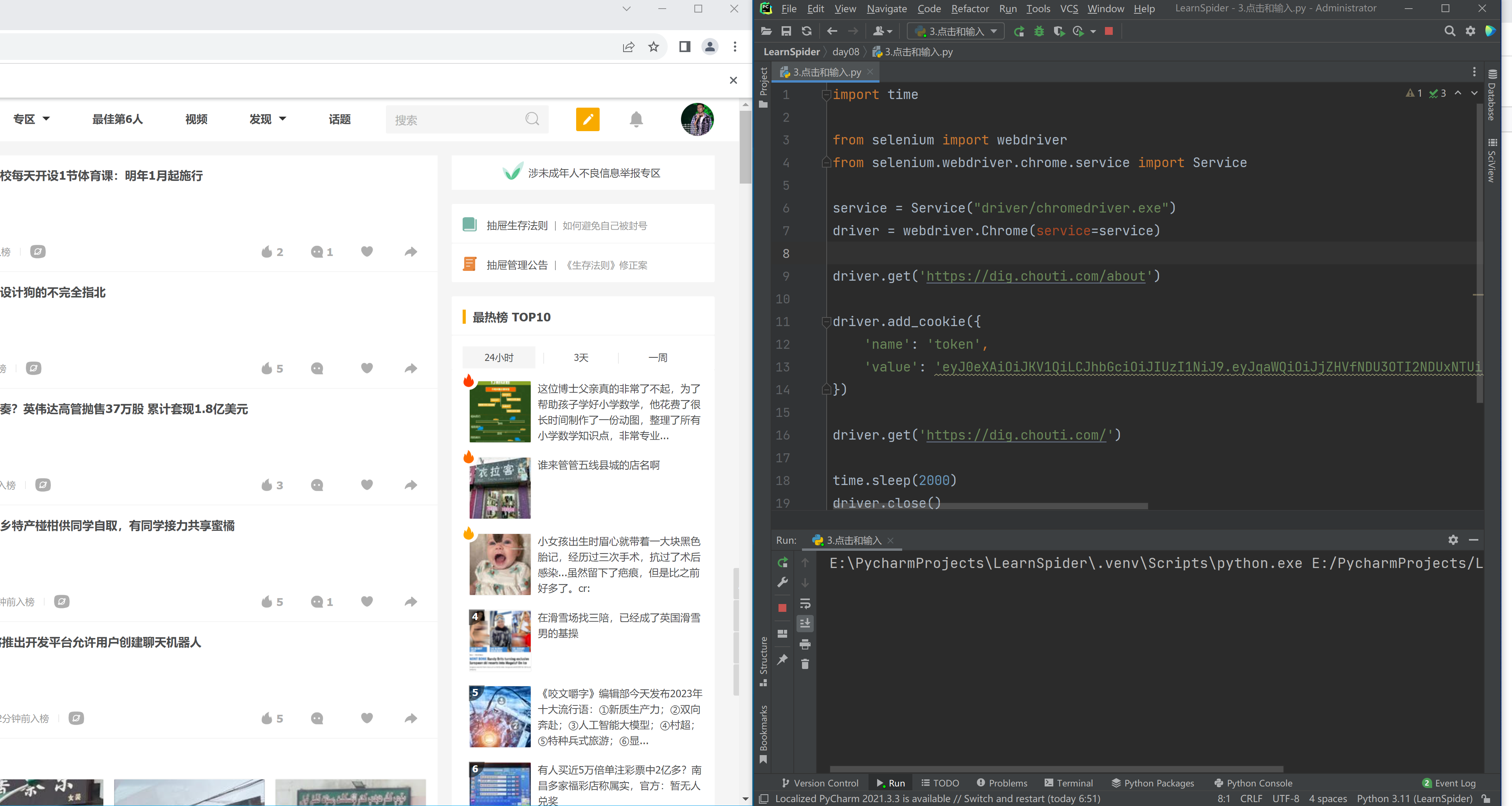
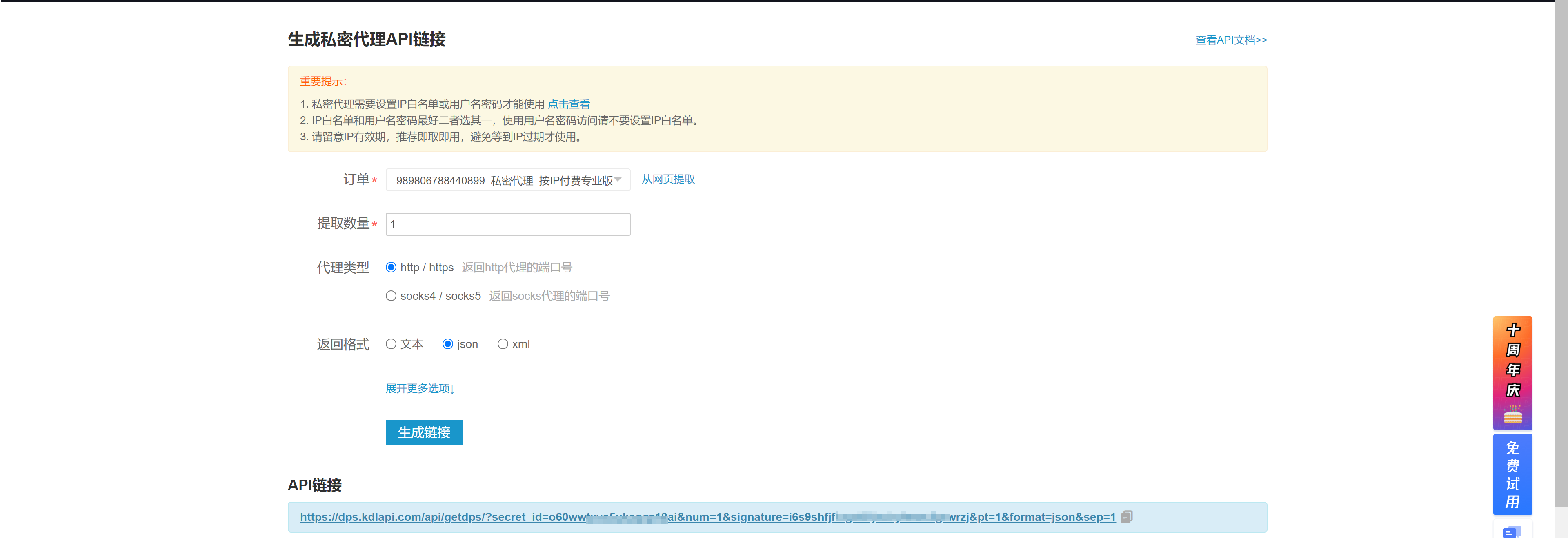
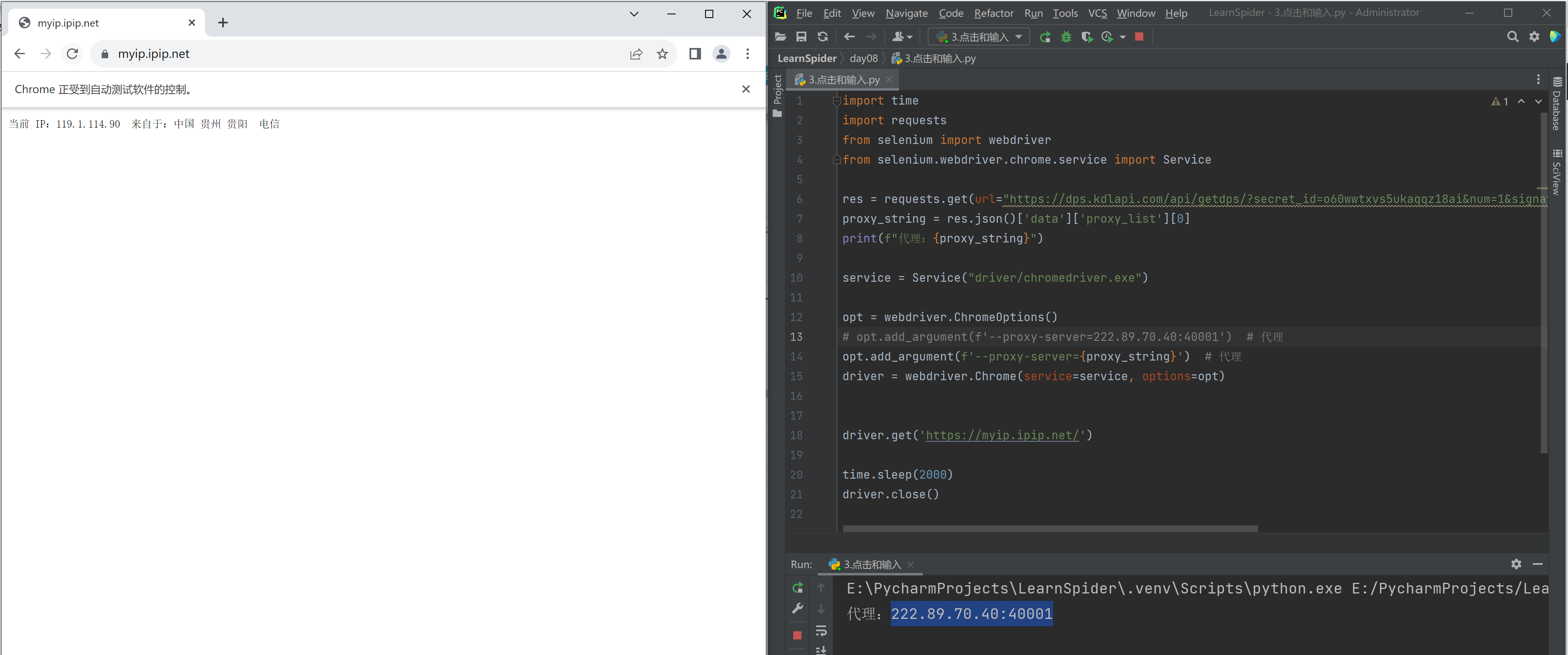
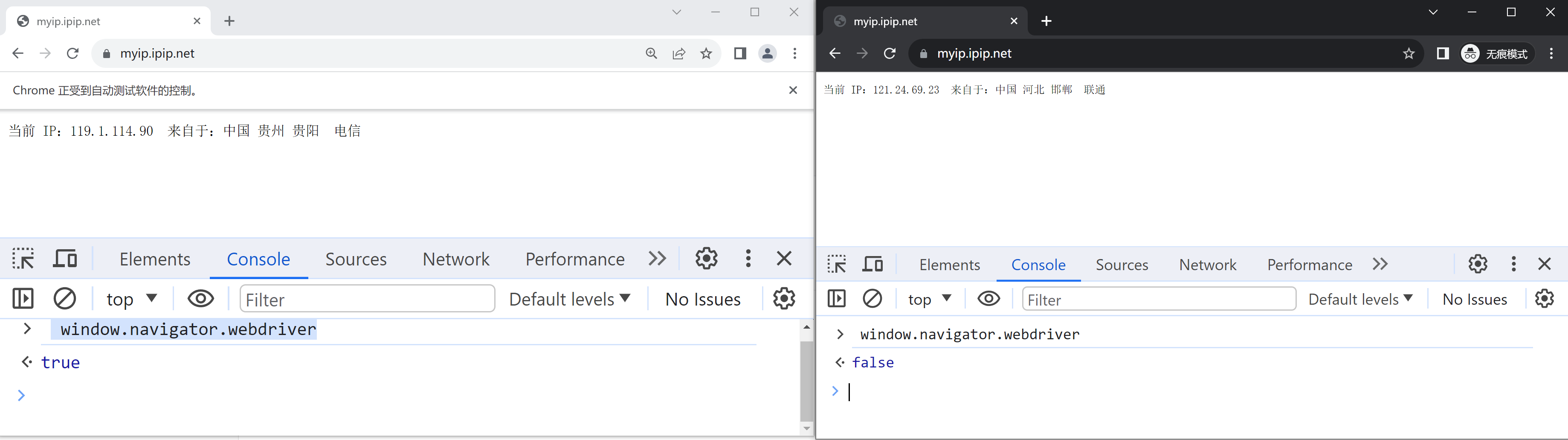
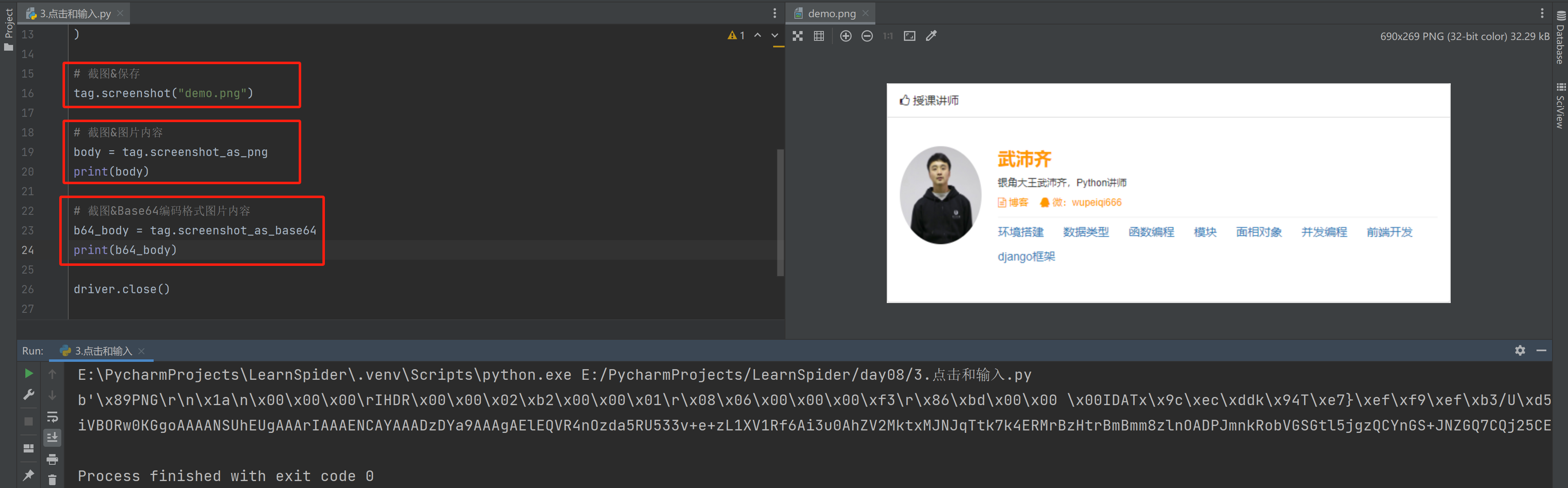
import time from selenium import webdriver from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.by import By
service = Service("driver/chromedriver.exe") driver = webdriver.Chrome(service=service)
driver.get('打开网址')
# find_element find_elements tag = driver.find_element(By.ID, "user") tag = driver.find_element(By.CLASS_NAME, "c1") tag = driver.find_element(By.TAG_NAME, "div") tag = driver.find_element(By.XPATH, "/html/body/div[1]/div/div[2]/div[3]/div[3]/div/div/div/div[1]/span[2]") tag = driver.find_element(By.XPATH, '//*[@id="geetest-wrap"]//input[@name="tel"]')
tag_list = driver.find_elements(By.XPATH, "/html/body/div/div[2]/div/div[2]/div/div[2]/div[2]/div/div/div/div/div[2]/a") for tag in tag_list: print(tag)
import time from selenium import webdriver from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.by import By
service = Service("driver/chromedriver.exe") driver = webdriver.Chrome(service=service)
driver.get('https://www.5xclass.cn/')
# 根据ID寻找 tag = driver.find_element(By.ID, "bs-example-navbar-collapse-1") print(tag.text) print(10 * "-")
# 根据类名寻找 tags = driver.find_elements(By.CLASS_NAME, "panel-heading") for tag in tags: print(tag.text) print(10 * "-")
# 根据标签名称寻找 tags = driver.find_elements(By.TAG_NAME, "li") for tag in tags: print(tag.text) print(10 * "-")
# 根据XPATH寻找 tag = driver.find_element(By.XPATH, "/html/body/div/div[2]/div/div[2]/div/div[2]/div[1]") print(tag.text) print(10 * "-")
# 根据XPATH寻找 tag = driver.find_element(By.XPATH, '//*[@id="bs-example-navbar-collapse-1"]/ul[1]/li[1]/a') print(tag.text) print(10 * "-")
# 根据XPATH寻找多个 tags = driver.find_elements(By.XPATH, '/html/body/div/div[2]/div/div[2]/div/div[2]/div[2]/div/div/div/div/div[2]/a') for tag in tags: print(tag.text) print(10 * "-")
# 根据父子关系嵌套寻找 parent = driver.find_element(By.XPATH, '/html/body/div/div[2]/div/div[2]/div/div[2]/div[2]/div/div/div/div') tags = parent.find_elements(By.XPATH, "div[@class='course']/a") for tag in tags: print(tag.text)
import time from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.chrome.service import Service from selenium.webdriver.support.wait import WebDriverWait
service = Service("driver/chromedriver.exe") driver = webdriver.Chrome(service=service)
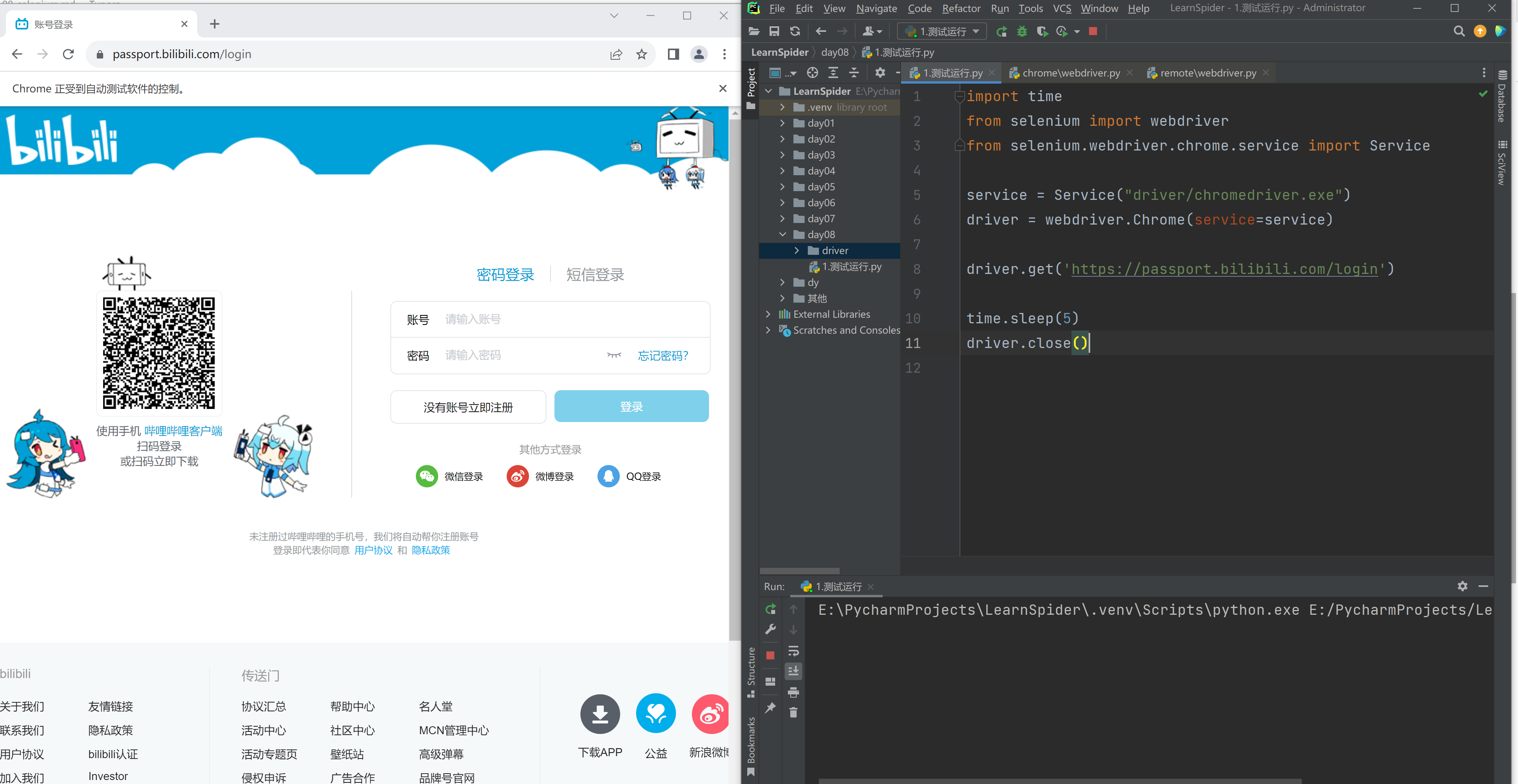
import time from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.chrome.service import Service from selenium.webdriver.support.wait import WebDriverWait
service = Service("driver/chromedriver.exe") driver = webdriver.Chrome(service=service)
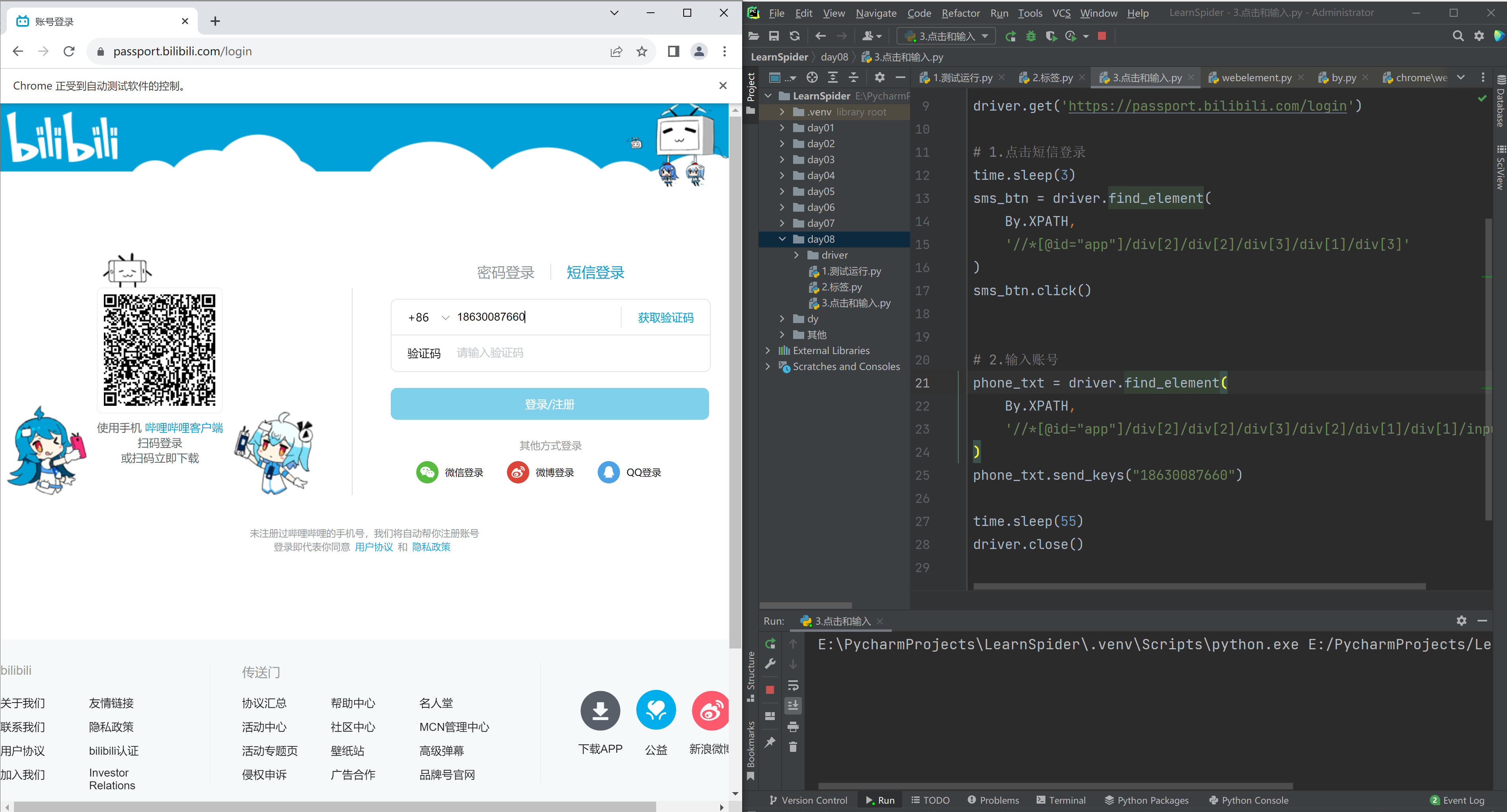
driver.get('https://passport.bilibili.com/login')
deffunc(dv): print("无返回值,则间隔0.5s执行一次此函数;如有返回值,则复制给sms_btn变量") # <div xxx="123" id="uuu"></div> # <img src="..."/> tag = dv.find_element( By.XPATH, '//*[@id="app"]/div[2]/div[2]/div[3]/div[1]/div[3]' ) img_src = tag.get_attribute("xxx") if img_src: return tag return
from selenium import webdriver from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.by import By service = Service("driver/chromedriver.exe") driver = webdriver.Chrome(service=service) driver.implicitly_wait(10)
driver.get('https://www.5xclass.cn')
tag = driver.find_element( By.XPATH, '/html/body/div/div[2]/div/div[2]/div/div[2]/div[2]/div/div/div/div/div[2]/a[1]' ) print(tag.text) print(tag.get_attribute("target")) print(tag.get_attribute("data-toggle"))
from selenium import webdriver from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.by import By from bs4 import BeautifulSoup
service = Service("driver/chromedriver.exe") driver = webdriver.Chrome(service=service) driver.implicitly_wait(10)
driver.get('https://car.yiche.com/')
html_string = driver.page_source
soup = BeautifulSoup(html_string, features="html.parser") tag_list = soup.find_all(name="div", attrs={"class": "item-brand"}) for tag in tag_list: child = tag.find(name='div', attrs={"class": "brand-name"}) print(child.text)
withopen('driver/hide.js') as f: driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": f.read()})
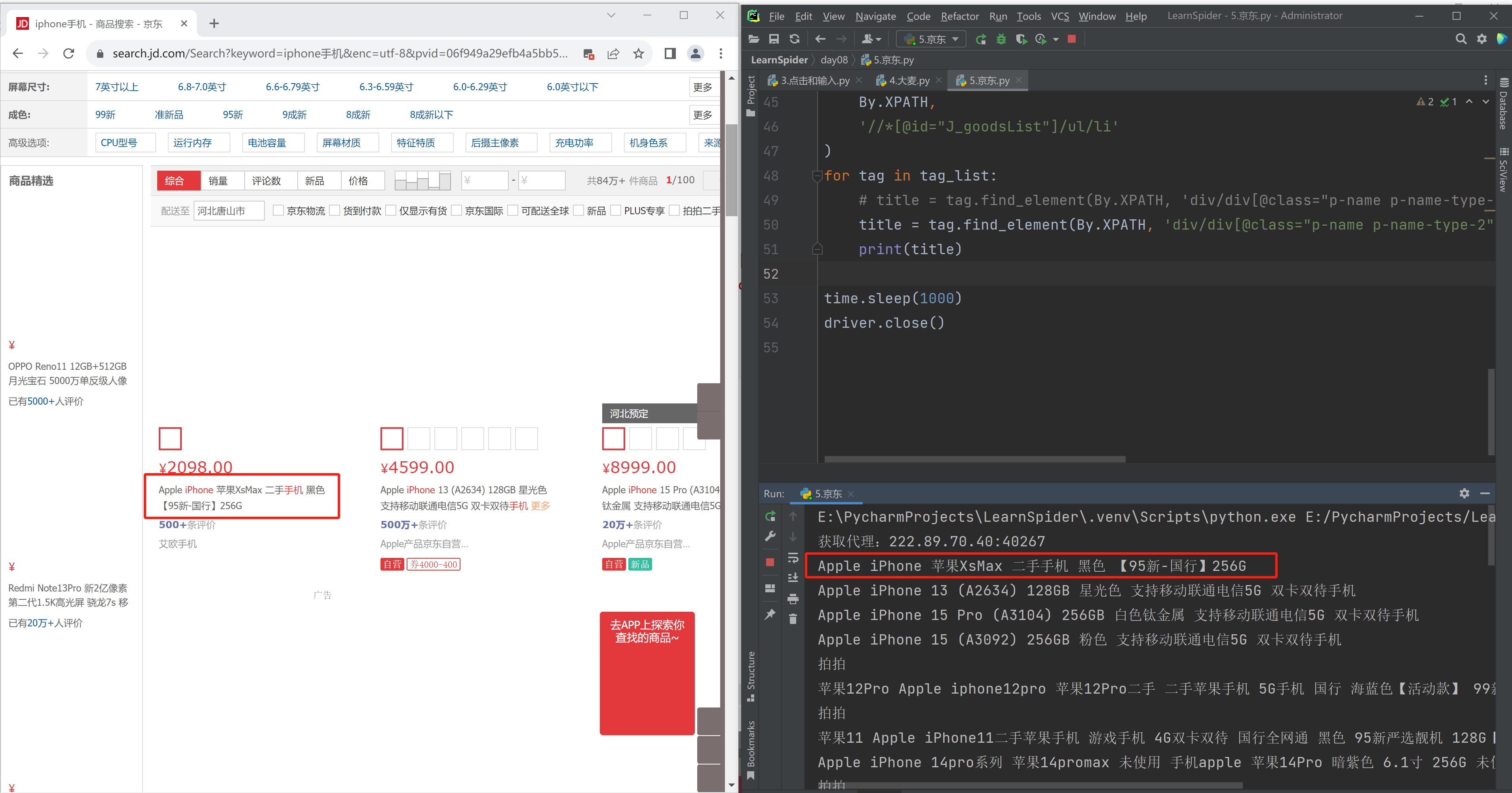
# 1.打开京东 driver.get('https://www.jd.com/')
# 2.搜索框+输入 tag = driver.find_element( By.XPATH, '//*[@id="key"]' ) tag.send_keys("iphone手机")
# 3.点击搜索 tag = driver.find_element( By.XPATH, '//*[@id="search"]/div/div[2]/button' ) tag.click()
# 4.查询列表 tag_list = driver.find_elements( By.XPATH, '//*[@id="J_goodsList"]/ul/li' ) for tag in tag_list: # title = tag.find_element(By.XPATH, 'div/div[@class="p-name p-name-type-2"]//em').text title = tag.find_element(By.XPATH, 'div/div[@class="p-name p-name-type-2"]/a/em').text print(title)
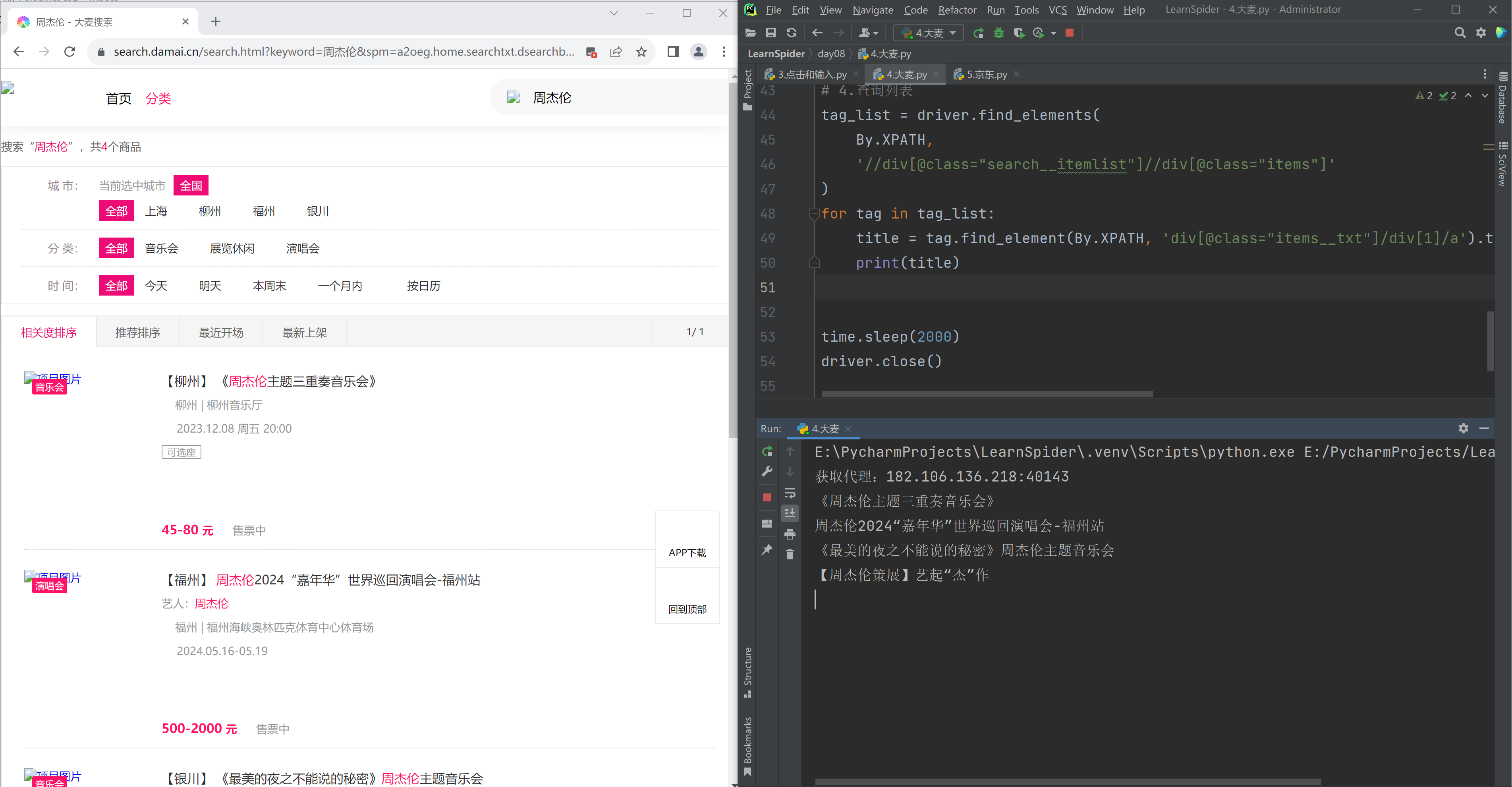
# 2.搜索框+输入 tag = driver.find_element( By.XPATH, '//input[@class="input-search"]' ) tag.send_keys("周杰伦")
# 3.点击搜索 tag = driver.find_element( By.XPATH, '//div[@class="btn-search"]' ) tag.click()
# 4.查询列表 tag_list = driver.find_elements( By.XPATH, '//div[@class="search__itemlist"]//div[@class="items"]' ) for tag in tag_list: title = tag.find_element(By.XPATH, 'div[@class="items__txt"]/div[1]/a').text print(title)