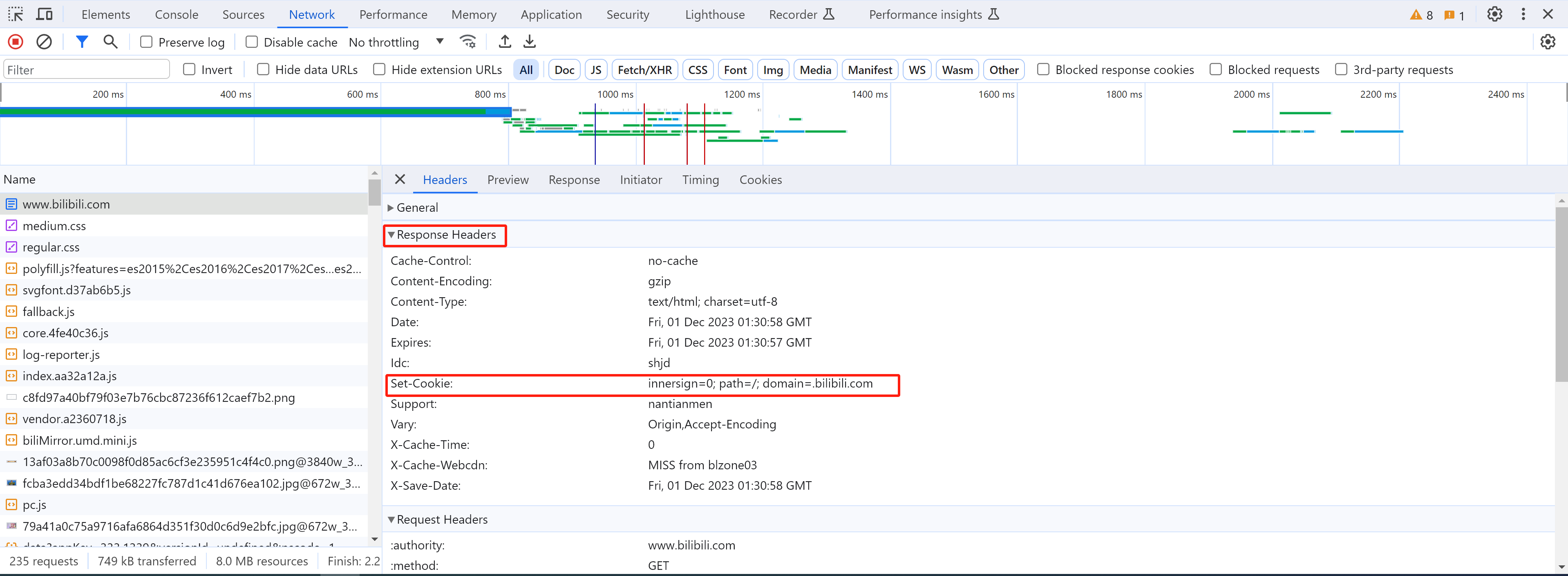
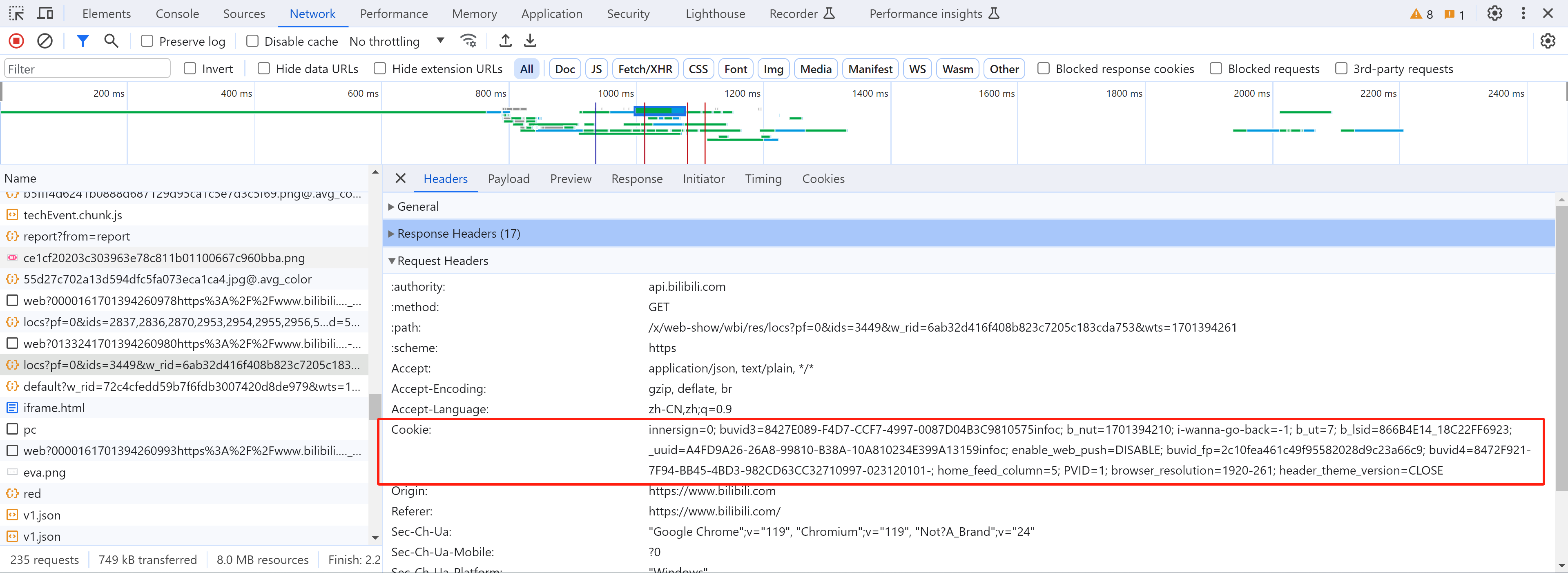
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
import requests
res = requests.post(
url="https://www.fuzhou.gov.cn/ssp/search/api/search?time=1701392708022",
data={
"siteType": "1",
"mainSiteId": "402849946077df37016077eea95e002f",
"siteId": "402849946077df37016077eea95e002f",
"type": "0",
"page": "1",
"rows": "10",
"historyId": "48908a988b85d1ee018c22e8a6e242c0",
"sourceType": "SSP_ZHSS",
"isChange": "0",
"fullKey": "N",
"wbServiceType": "13",
"fileType": "",
"fileNo": "",
"pubOrg": "",
"themeType": "",
"searchTime": "",
"startDate": "",
"endDate": "",
"sortFiled": "RELEVANCE",
"searchFiled": "",
"dirUseLevel": "",
"issueYear": "",
"issueMonth": "",
"allKey": "",
"fullWord": "",
"oneKey": "",
"notKey": "",
"totalIssue": "",
"chnlName": "",
"zfgbTitle": "",
"zfgbContent": "",
"zfgbPubOrg": "",
"zwgkPubDate": "",
"zwgkDoctitle": "",
"zwgkDoccontent": "",
"zhPubOrg": "1",
"keyWord": "编程",
"pubOrgType": "",
"zhuTiIdList": "",
"feaTypeName": "",
"jiGuanList": "",
"publishYear": ""
},
headers={
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
}
)
print(res.text)
|